프라이머리 인덱스
이 페이지에서는 ClickHouse의 희소 기본 인덱스가 어떻게 구성되고 동작하는지, 그리고 쿼리 실행을 어떻게 가속하는지 소개합니다.
더 고급 인덱싱 전략과 심화된 기술적 내용을 확인하려면 기본 인덱스 심층 가이드를 참고하십시오.
ClickHouse에서 희소 기본 인덱스는 어떻게 동작합니까?
ClickHouse의 희소 기본 인덱스는 그래뉼—여러 행으로 이루어진 블록—이 테이블의 ^^primary key^^ 컬럼에 대한 쿼리의 조건과 일치하는 데이터를 포함할 수 있는지 효율적으로 식별하는 데 도움이 됩니다. 다음 절에서는 이 인덱스가 해당 컬럼들의 값에서 어떻게 구성되는지 설명합니다.
희소 기본 인덱스 생성
희소 기본 인덱스가 어떻게 구성되는지 설명하기 위해, 몇 가지 애니메이션과 함께 uk_price_paid_simple 테이블을 사용합니다.
다시 상기하자면, ① ^^기본 키^^가 (town, street)인 예제 테이블에서 ② 삽입된 데이터는 ③ 디스크에 저장되며, ^^기본 키^^ 컬럼 값으로 정렬되고 압축되며, 각 컬럼마다 별도의 파일에 저장됩니다:
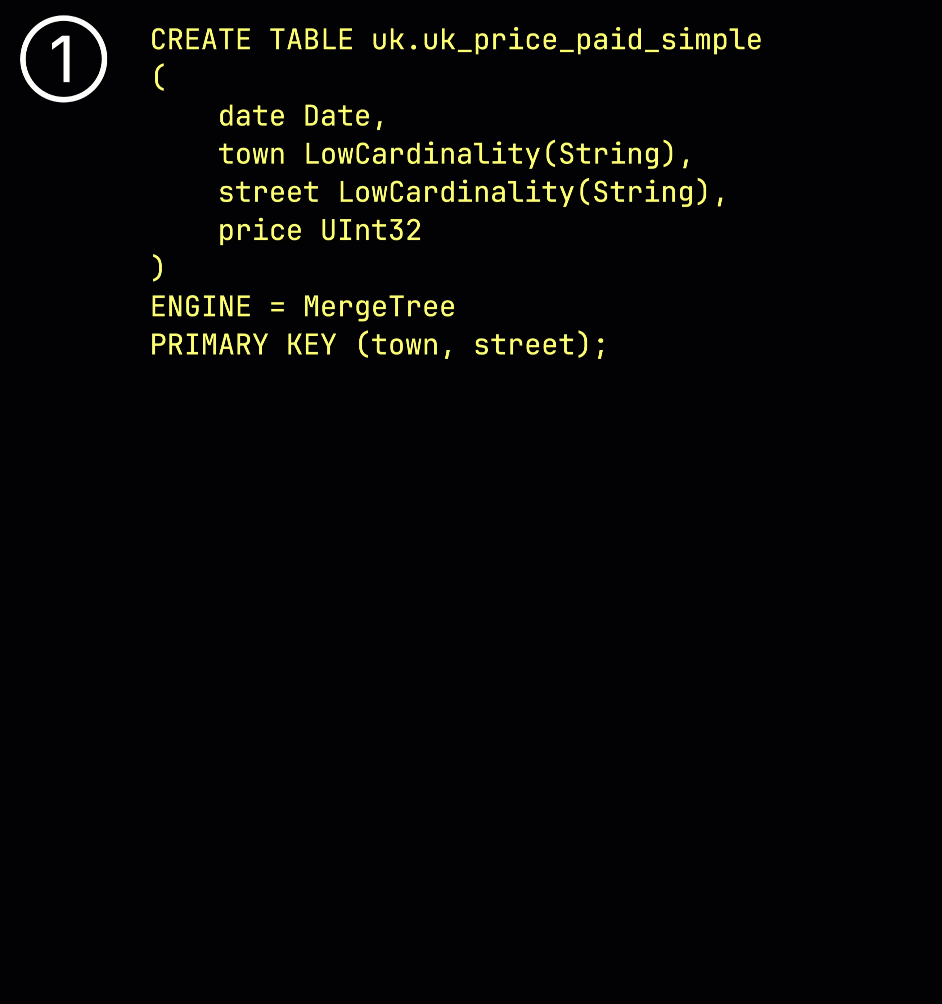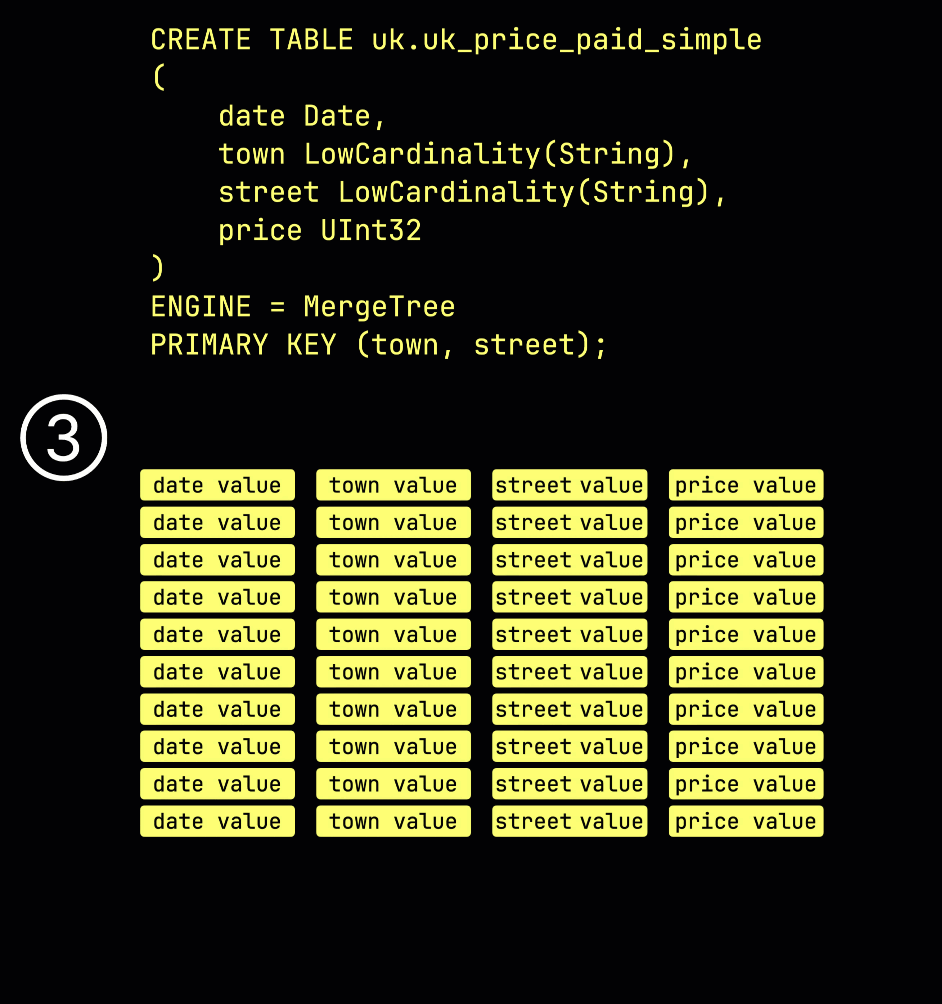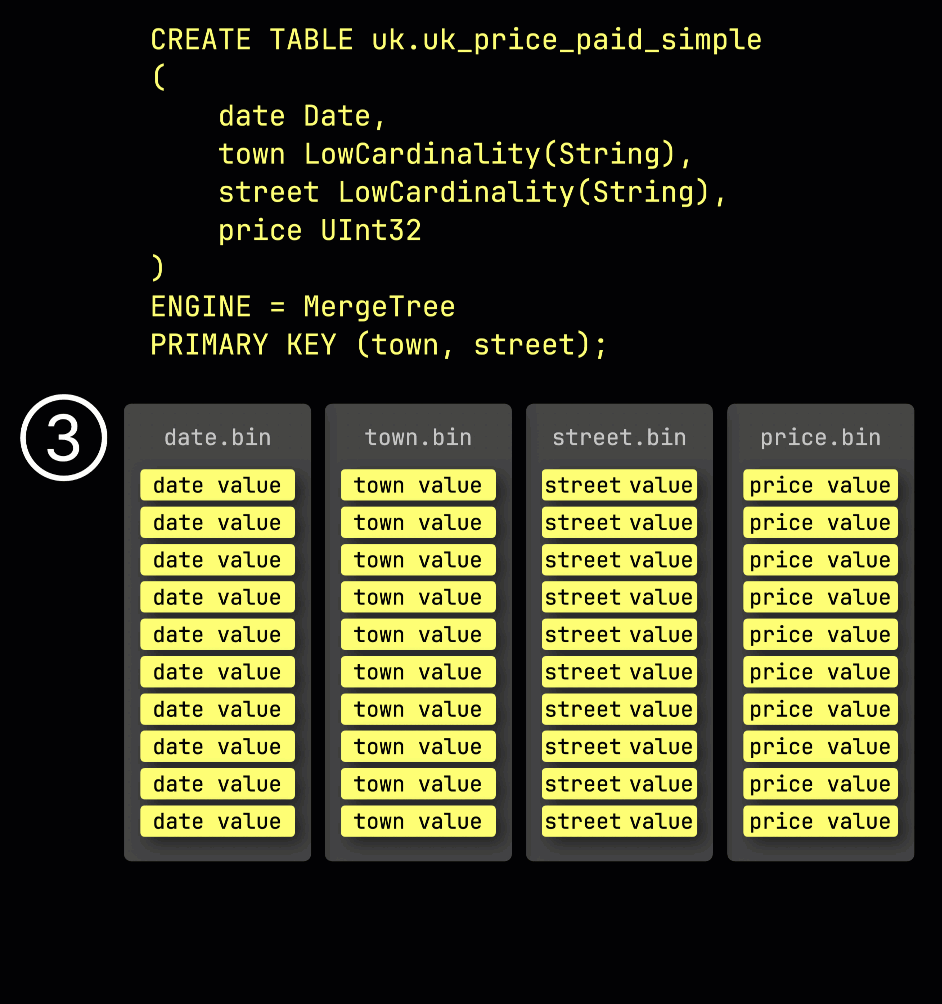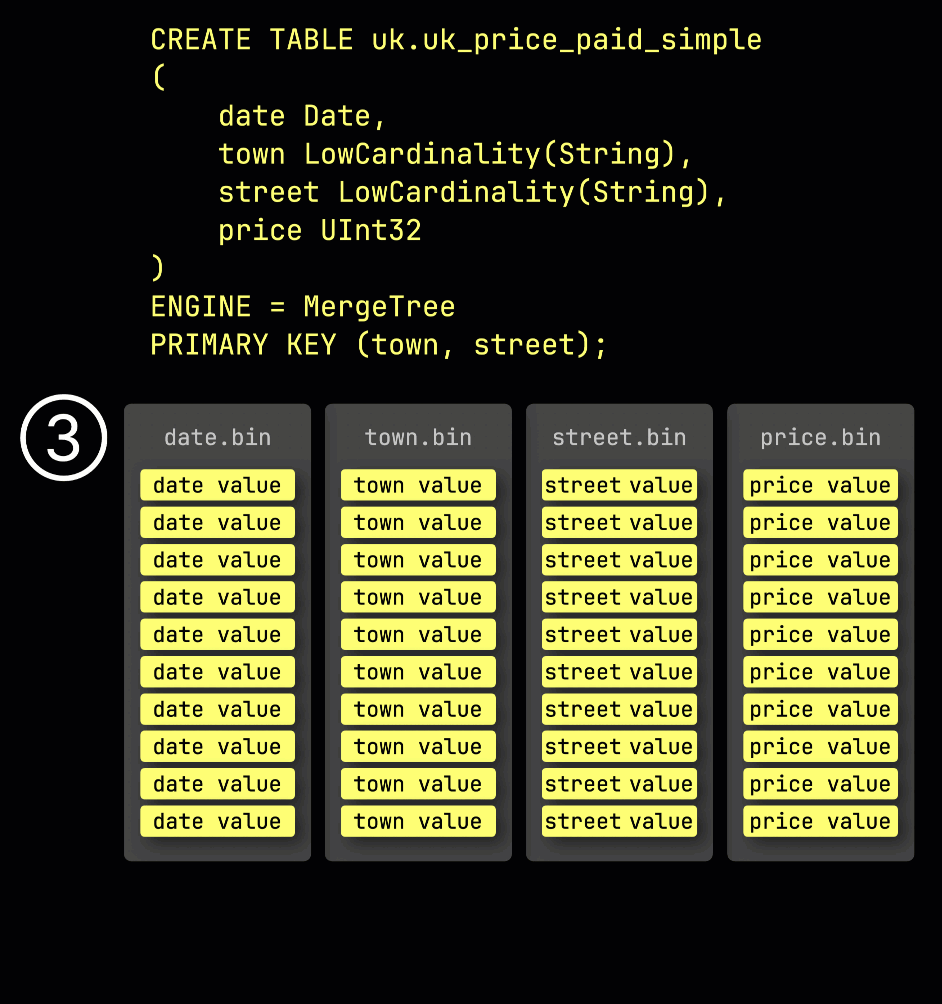
처리를 위해 각 컬럼의 데이터는 ④ 논리적으로 그래뉼로 분할되며, 각 그래뉼은 8,192개의 행을 포함합니다. 이는 ClickHouse의 데이터 처리 메커니즘이 동작하는 최소 단위입니다.
이 ^^그래뉼^^ 구조는 기본 인덱스를 희소하게 만드는 요소이기도 합니다. 모든 행을 인덱싱하는 대신, ClickHouse는 각 ^^그래뉼^^에서 단 하나의 행—구체적으로는 첫 번째 행—의 ^^기본 키^^ 값만 ⑤ 저장합니다. 그 결과 ^^그래뉼^^당 인덱스 엔트리가 하나씩 존재하게 됩니다:
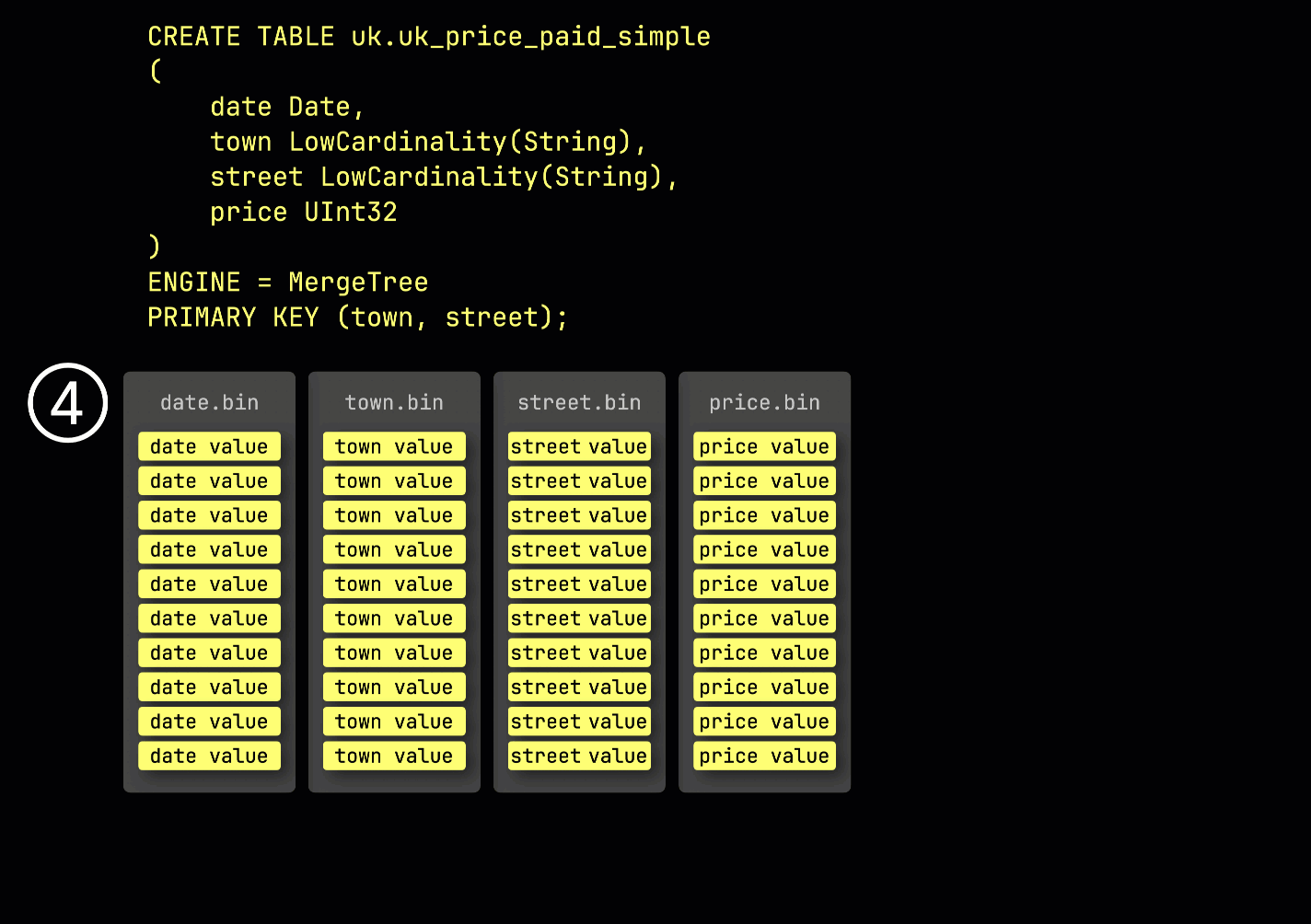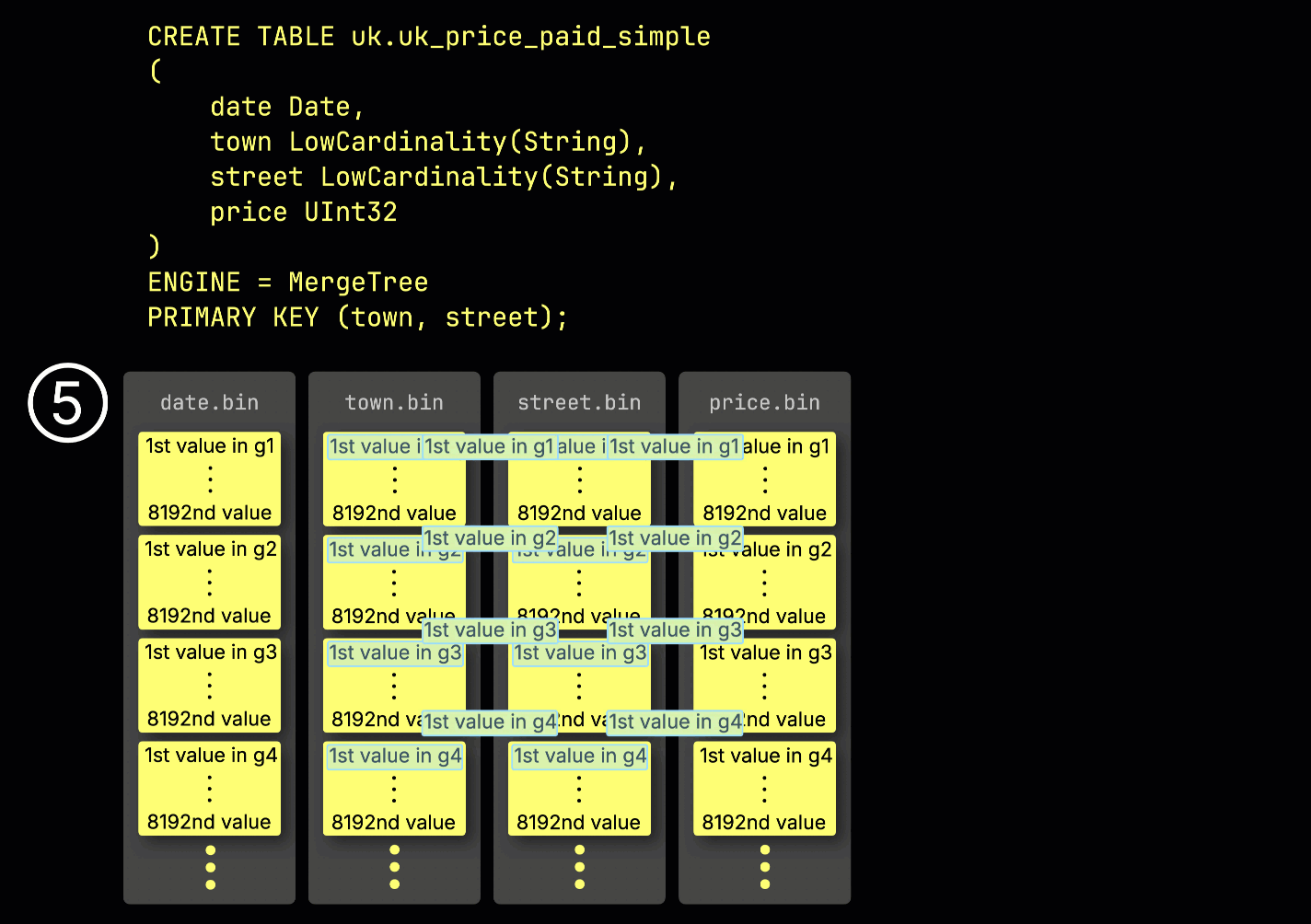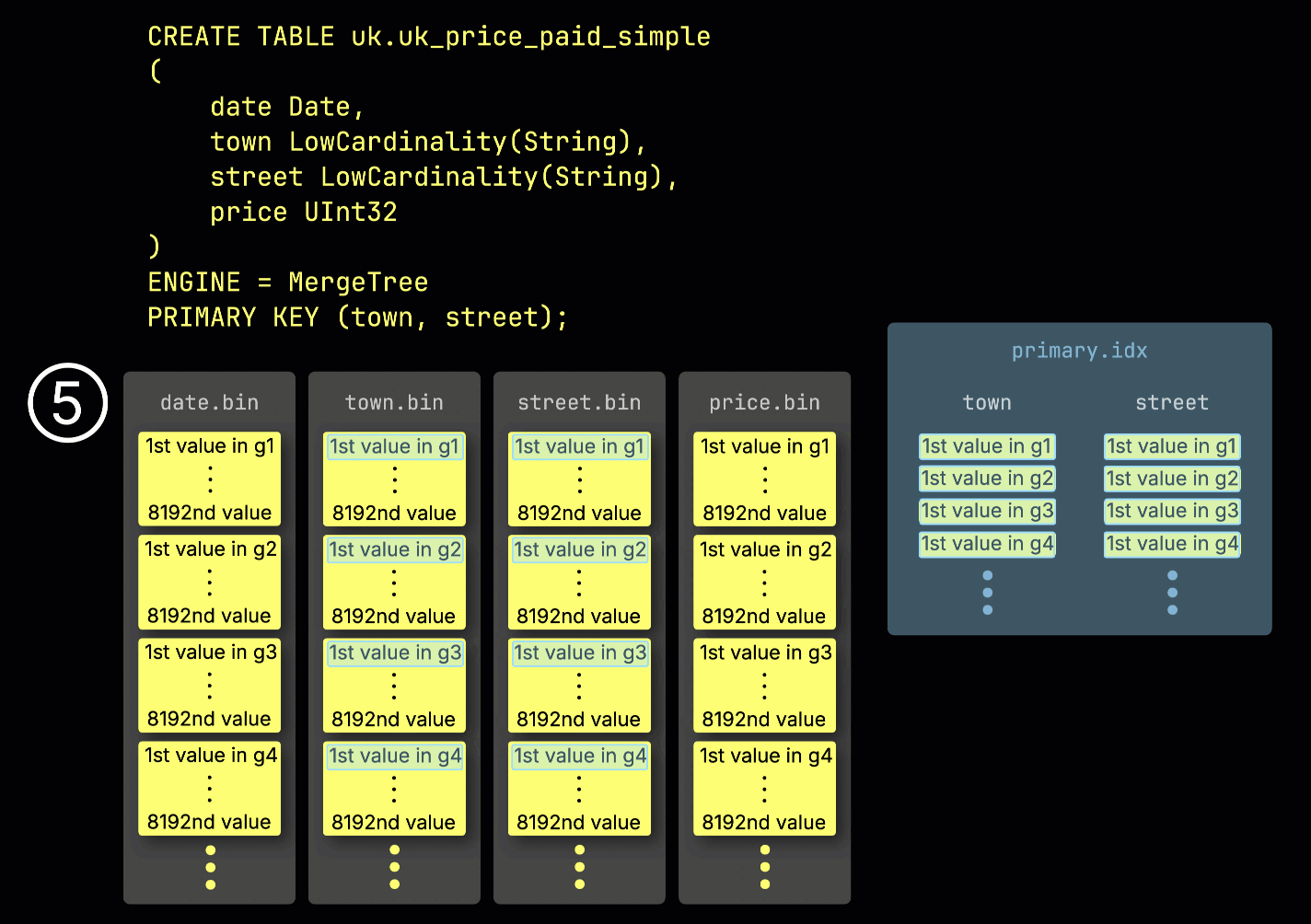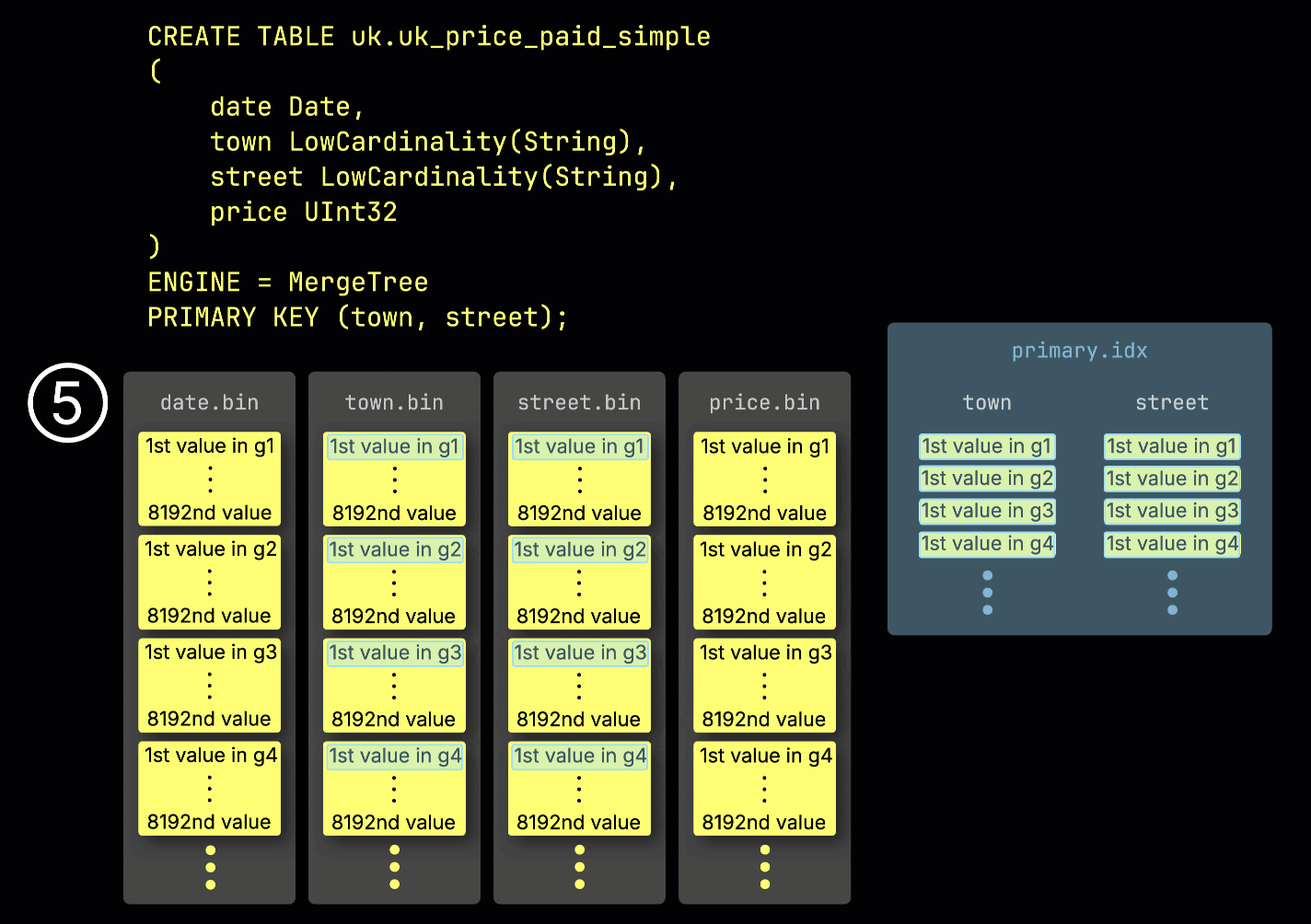
희소성 덕분에 기본 인덱스는 전체가 메모리에 상주할 만큼 충분히 작게 유지되며, ^^기본 키^^ 컬럼에 대한 조건이 있는 쿼리에서 빠른 필터링을 가능하게 합니다. 다음 섹션에서는 이 인덱스가 이러한 쿼리를 어떻게 가속하는지 살펴봅니다.
기본 인덱스 사용 방법
희소 기본 인덱스가 쿼리 가속에 어떻게 사용되는지 다른 애니메이션을 통해 간략히 설명합니다:
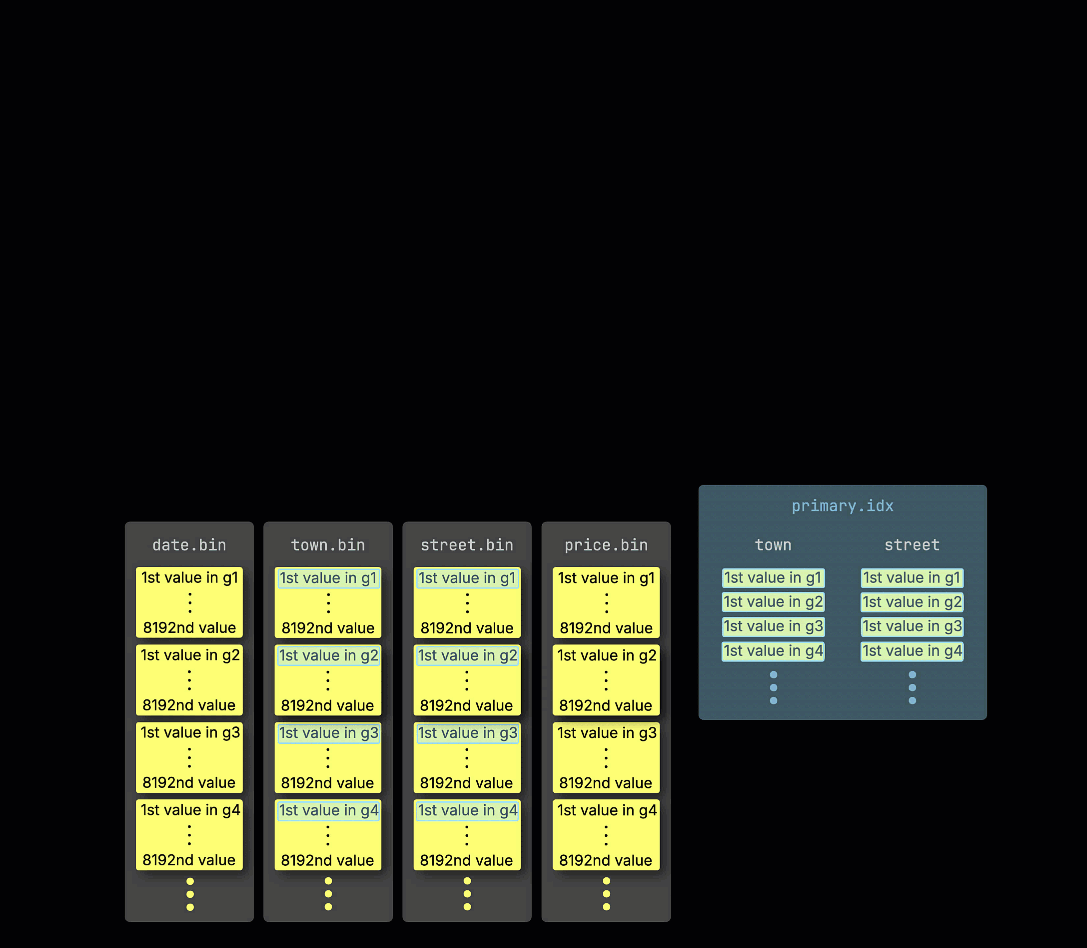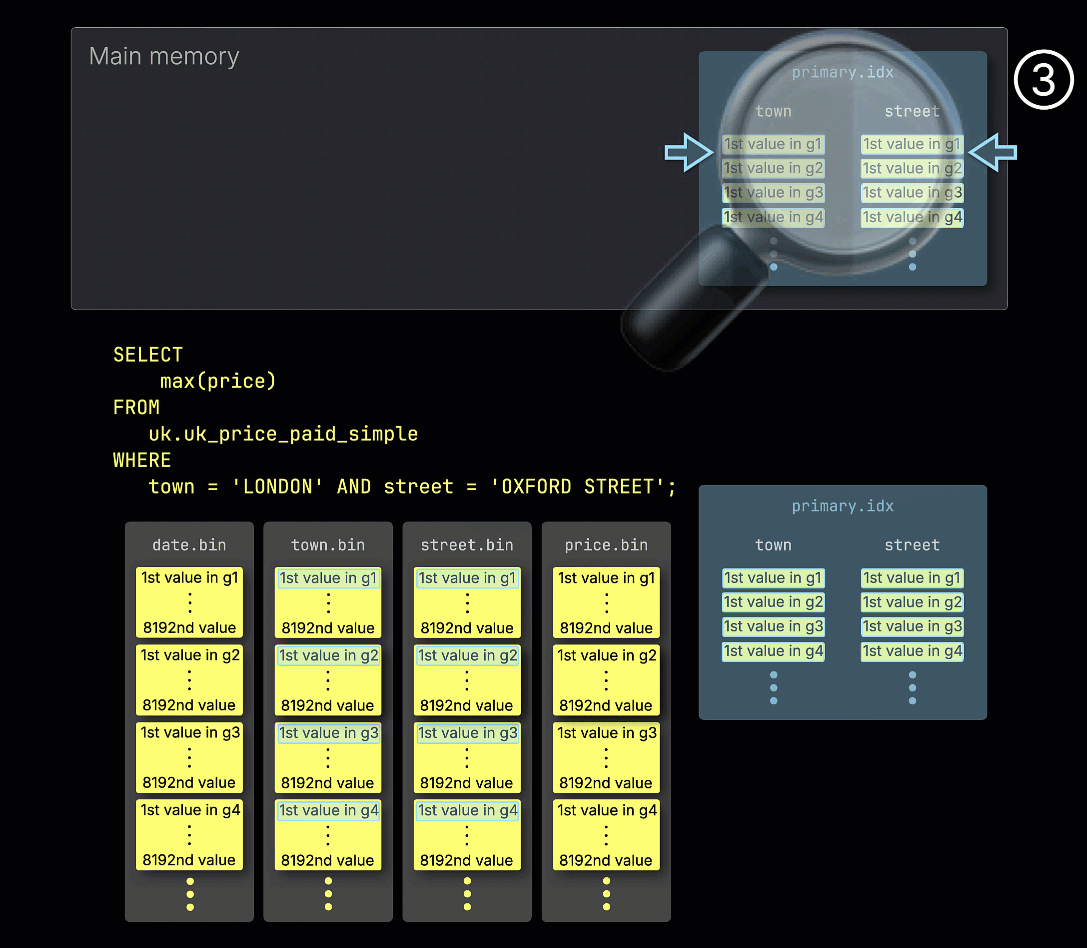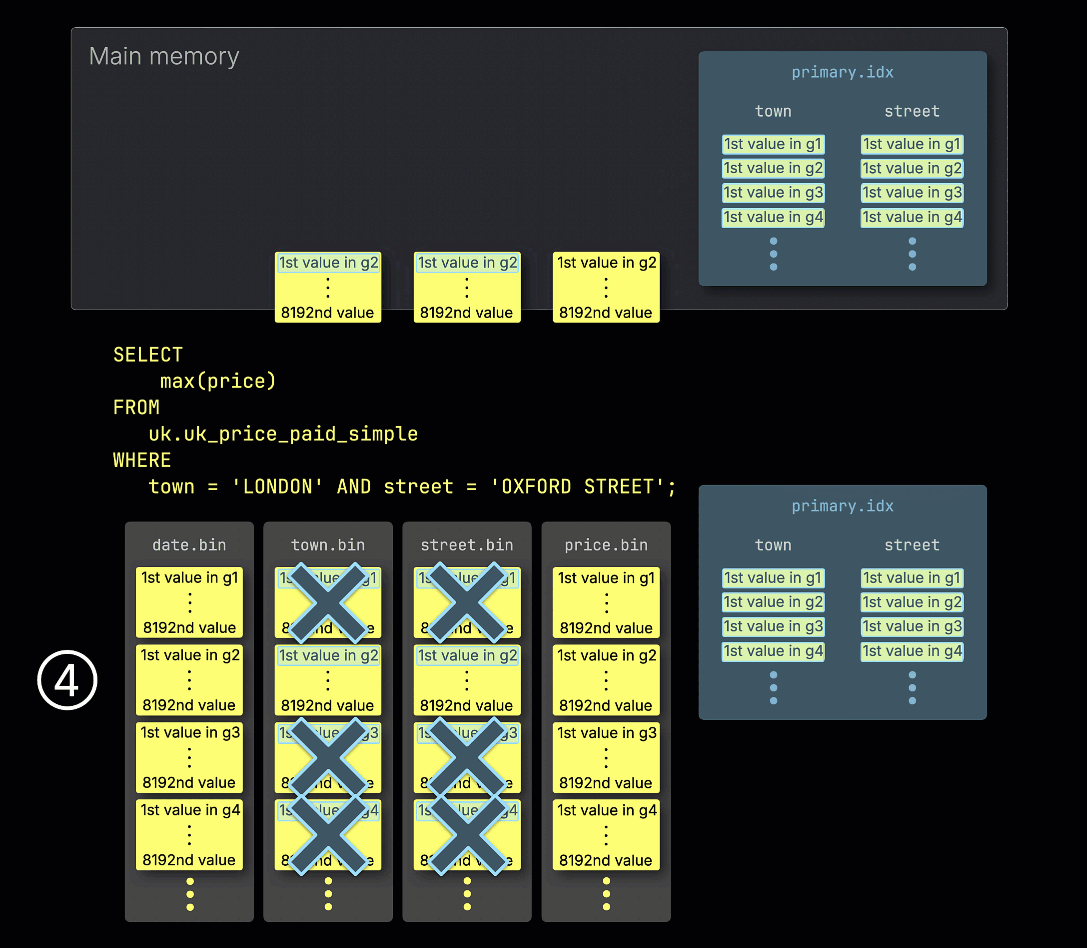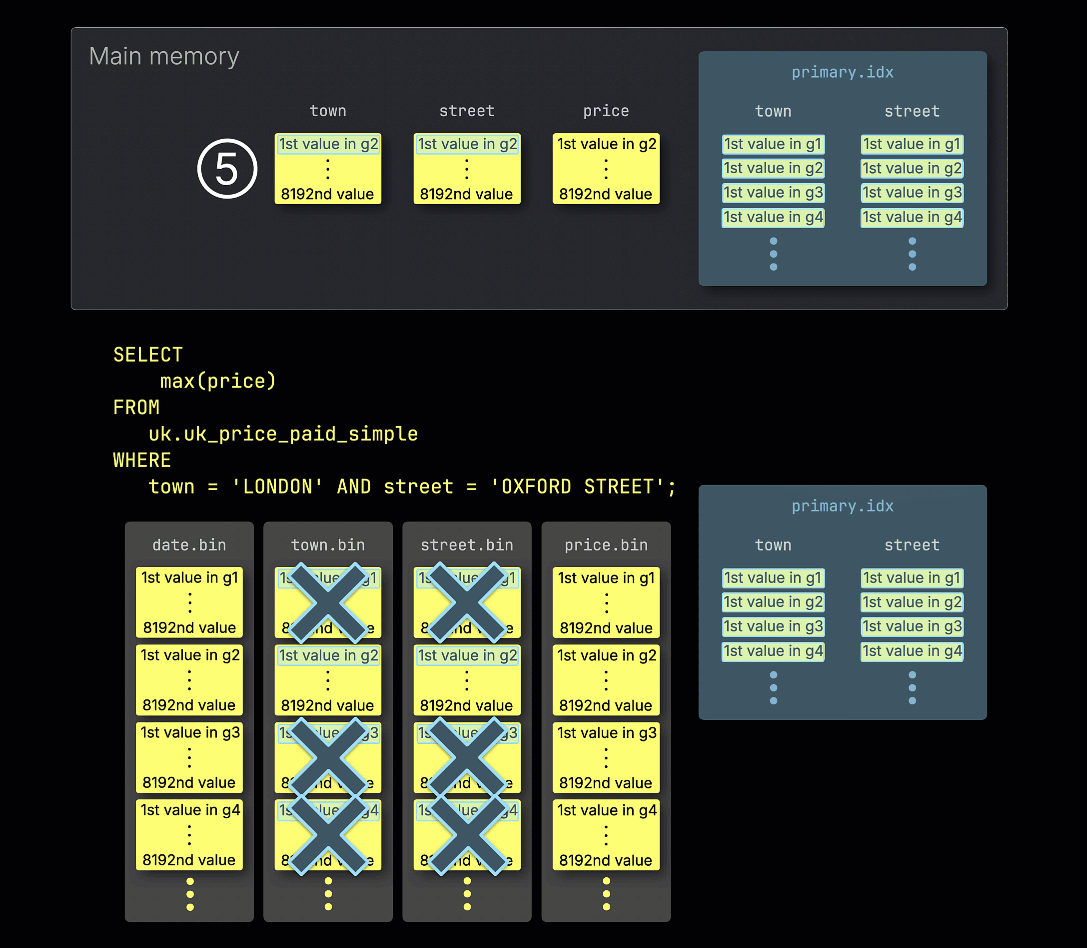
① 예제 쿼리에는 두 ^^primary key^^ 컬럼 모두에 대한 조건이 포함됩니다: town = 'LONDON' AND street = 'OXFORD STREET'.
② 쿼리를 가속하기 위해 ClickHouse는 테이블의 기본 인덱스를 메모리에 로드합니다.
③ 그런 다음 인덱스 엔트리를 스캔하여 조건과 일치하는 행을 포함할 수 있는 그래뉼이 어떤 것들인지, 다시 말해 건너뛸 수 없는 그래뉼이 무엇인지 식별합니다.
④ 이렇게 잠재적으로 관련 있는 그래뉼을 메모리에 로드하고, 쿼리에 필요한 다른 컬럼의 해당 그래뉼과 함께 메모리에서 처리합니다.
기본 인덱스 모니터링
테이블의 각 데이터 파트는 자체 기본 인덱스를 가지고 있습니다. mergeTreeIndex 테이블 함수로 이러한 인덱스의 내용을 확인할 수 있습니다.
다음 쿼리는 예제 테이블의 각 데이터 파트별로 기본 인덱스에 있는 항목 개수를 나열합니다.
이 쿼리는 현재 존재하는 데이터 ^^파트^^ 중 하나의 프라이머리 인덱스에서 첫 10개 항목을 보여줍니다. 이러한 ^^파트^^는 백그라운드에서 지속적으로 더 큰 ^^파트^^로 병합됩니다.
마지막으로 EXPLAIN 절을 사용하여, 모든 데이터 ^^파트^^의 기본 인덱스(primary index)가 예제 쿼리의 조건과 일치하는 행을 포함할 가능성이 전혀 없는 그래뉼을 어떻게 건너뛰는지 확인합니다. 이러한 그래뉼은 로딩 및 처리에서 제외됩니다:
위의 EXPLAIN 출력에서 13번째 행을 보면, 전체 데이터 ^^파트^^에 걸쳐 존재하는 3,609개의 그래뉼 중 단 3개만이 기본 인덱스(primary index) 분석을 통해 처리 대상으로 선택되었음을 알 수 있습니다. 나머지 그래뉼은 모두 완전히 건너뛰었습니다.
또한 쿼리를 단순히 실행해 보기만 해도 대부분의 데이터가 건너뛰어졌음을 확인할 수 있습니다.
위에서 본 것처럼 예제 테이블의 약 3,000만 행 가운데 약 2만5,000행만 처리되었습니다:
핵심 요약
-
희소 기본 인덱스는 ClickHouse가 ^^기본 키(primary key)^^ 컬럼의 쿼리 조건과 일치하는 행을 포함할 가능성이 있는 그래뉼을 식별하여 불필요한 데이터를 건너뛸 수 있도록 돕습니다.
-
각 인덱스는 각 ^^그래뉼^^의 첫 번째 행의 ^^기본 키(primary key)^^ 값만 저장합니다(기본적으로 하나의 ^^그래뉼^^은 8,192개의 행을 가집니다). 이렇게 함으로써 메모리에 적재할 수 있을 만큼 충분히 작게 유지됩니다.
-
^^MergeTree^^ 테이블의 **각 데이터 파트(data part)**는 자체 기본 인덱스를 가지며, 쿼리 실행 중에 서로 독립적으로 사용됩니다.
-
쿼리 수행 중 인덱스를 사용하면 ClickHouse가 그래뉼을 건너뛰어 I/O와 메모리 사용량을 줄이고 성능을 향상시킬 수 있습니다.
-
mergeTreeIndex테이블 함수를 사용하여 인덱스 내용을 확인하고,EXPLAIN절을 사용하여 인덱스 사용 현황을 모니터링할 수 있습니다.
추가 정보
희소 기본 키 인덱스가 ClickHouse에서 어떻게 동작하는지, 기존 데이터베이스 인덱스와 어떤 차이가 있는지, 그리고 활용 시 모범 사례가 무엇인지 더 깊이 살펴보려면 인덱싱을 심층적으로 다룬 상세 가이드를 참고하십시오.
기본 키 인덱스 검색으로 선택된 데이터를 ClickHouse가 어떻게 고도로 병렬 처리하는지에 대해 알아보려면 쿼리 병렬 처리 가이드는 여기를 참조하십시오.
