ClickStack과 Elastic의 대응 개념
Elastic Stack vs ClickStack
Elastic Stack과 ClickStack은 모두 관측성 플랫폼의 핵심 역할을 지원하지만, 이러한 역할을 수행하는 설계 철학은 서로 다릅니다. 이러한 역할에는 다음이 포함됩니다:
- UI 및 알림: 데이터 쿼리, 대시보드 작성, 알림 관리를 위한 도구
- 스토리지 및 쿼리 엔진: 관측성 데이터를 저장하고 분석용 쿼리를 처리하는 백엔드 시스템
- 데이터 수집 및 ETL: 텔레메트리 데이터를 수집하고 수집 전에 처리하는 에이전트와 파이프라인
아래 표는 각 스택이 구성 요소를 이러한 역할에 어떻게 매핑하는지 보여줍니다:
| Role | Elastic Stack | ClickStack | Comments |
|---|---|---|---|
| UI & Alerting | Kibana — 대시보드, 검색, 알림 | ClickStack UI (HyperDX) — 실시간 UI, 검색, 알림 | 둘 다 시각화와 알림 관리를 포함하여 사용자에게 제공되는 기본 인터페이스 역할을 합니다. ClickStack UI는 관측성을 위해 설계되었으며 OpenTelemetry 시맨틱과 긴밀하게 결합되어 있습니다. |
| Storage & Query Engine | Elasticsearch — 역색인(inverted index)을 사용하는 JSON 문서 저장소 | ClickHouse — 벡터화된 엔진을 사용하는 컬럼 지향 데이터베이스 | Elasticsearch는 검색에 최적화된 역색인을 사용하고, ClickHouse는 구조화 및 반구조화 데이터에 대한 고속 분석을 위해 열 지향 스토리지와 SQL을 사용합니다. |
| Data Collection | Elastic Agent, Beats(예: Filebeat, Metricbeat) | OpenTelemetry Collector(edge + gateway) | Elastic은 커스텀 shipper와 Fleet에서 관리되는 통합 에이전트를 지원합니다. ClickStack은 OpenTelemetry에 기반하여 벤더 중립적인 데이터 수집 및 처리를 가능하게 합니다. |
| Instrumentation SDKs | Elastic APM agents(독점) | OpenTelemetry SDKs(ClickStack에서 배포) | Elastic SDK는 Elastic 스택에 종속됩니다. ClickStack은 주요 언어에서 로그, 메트릭, 트레이스를 위해 OpenTelemetry SDKs 위에 구축합니다. |
| ETL / Data Processing | Logstash, ingest 파이프라인 | OpenTelemetry Collector + ClickHouse materialized views | Elastic은 변환을 위해 ingest 파이프라인과 Logstash를 사용합니다. ClickStack은 materialized views와 데이터를 효율적이고 점진적으로 변환하는 OTel collector processor를 통해 연산을 쿼리 시점이 아니라 데이터 삽입 시점으로 이동합니다. |
| Architecture Philosophy | 수직 통합, 독점 에이전트 및 포맷 | 개방형 표준 기반, 느슨하게 결합된 구성 요소 | Elastic은 긴밀하게 통합된 생태계를 구축합니다. ClickStack은 유연성과 비용 효율성을 위해 모듈성과 표준(OpenTelemetry, SQL, 객체 스토리지)을 중시합니다. |
ClickStack은 수집부터 UI까지 전 구간에 걸쳐 OpenTelemetry 네이티브 플랫폼으로서, 개방형 표준과 상호운용성을 강조합니다. 반면 Elastic은 독점 에이전트와 포맷을 사용하는, 보다 강하게 수직 통합된 긴밀한 생태계를 제공합니다.
각 스택에서 데이터 저장, 처리, 쿼리를 담당하는 핵심 엔진이 Elasticsearch와 ClickHouse이므로, 이 둘의 차이를 이해하는 것이 중요합니다. 이러한 시스템은 전체 관측성 아키텍처의 성능, 확장성, 유연성을 떠받치는 기반입니다. 다음 섹션에서는 Elasticsearch와 ClickHouse의 주요 차이점, 즉 데이터 모델링 방식, 수집 처리 방식, 쿼리 실행 방식, 스토리지 관리 방식을 살펴봅니다.
Elasticsearch vs ClickHouse
ClickHouse와 Elasticsearch는 서로 다른 기반 모델을 사용해 데이터를 구성하고 쿼리하지만, 많은 핵심 개념은 유사한 역할을 합니다. 이 섹션에서는 Elastic에 익숙한 사용자를 위해 주요 개념의 대응 관계를 정리하고, 이를 ClickHouse의 개념에 매핑합니다. 용어는 다르지만, 대부분의 관측성 워크플로는 ClickStack에서 재현할 수 있으며, 많은 경우 더 효율적으로 수행할 수 있습니다.
핵심 구조 개념
| Elasticsearch | ClickHouse / SQL | 설명 |
|---|---|---|
| Field | Column | 데이터의 기본 단위로, 특정 타입의 하나 이상의 값을 보관합니다. Elasticsearch 필드는 원시 타입뿐 아니라 배열과 객체도 저장할 수 있습니다. 하나의 필드는 한 가지 타입만 가질 수 있습니다. ClickHouse 역시 배열과 객체(Tuples, Maps, Nested)를 지원하며, 컬럼이 여러 타입을 가질 수 있도록 하는 Variant 및 Dynamic과 같은 동적 타입도 지원합니다. |
| Document | Row | 필드(컬럼)의 집합입니다. Elasticsearch 도큐먼트는 기본적으로 더 유연하여, 데이터에 따라 새로운 필드가 동적으로 추가되며(타입은 데이터에서 자동으로 추론됨) 동작합니다. ClickHouse 행은 기본적으로 스키마에 의해 고정된 구조를 가지며, 사용자는 행에 대해 모든 컬럼 또는 그 일부를 삽입해야 합니다. ClickHouse의 JSON 타입은 삽입된 데이터를 기반으로 이와 동등한 수준의 반정형 동적 컬럼 생성을 지원합니다. |
| Index | Table | 쿼리 실행과 스토리지의 단위입니다. 두 시스템 모두에서 쿼리는 행/도큐먼트를 저장하는 인덱스 또는 테이블을 대상으로 실행됩니다. |
| Implicit | 스키마(SQL) | SQL 스키마는 테이블을 네임스페이스로 그룹화하며, 주로 접근 제어에 사용됩니다. Elasticsearch와 ClickHouse에는 스키마 개념이 없지만, 둘 다 역할과 RBAC를 통해 행 및 테이블 수준 보안을 지원합니다. |
| Cluster | Cluster / Database | Elasticsearch 클러스터는 하나 이상의 인덱스를 관리하는 런타임 인스턴스입니다. ClickHouse에서 데이터베이스는 테이블을 논리적 네임스페이스 안에 구성하여, Elasticsearch의 클러스터와 동일한 논리적 그룹화를 제공합니다. ClickHouse 클러스터는 Elasticsearch와 유사한 분산 노드 집합이지만, 데이터 자체와는 분리되어 독립적으로 동작합니다. |
데이터 모델링과 유연성
Elasticsearch는 dynamic mappings을 통한 스키마 유연성으로 잘 알려져 있습니다. 문서가 수집되는 대로 필드가 생성되고, 스키마를 명시하지 않는 한 타입이 자동으로 추론됩니다. ClickHouse는 기본적으로 더 엄격하여 테이블을 명시적인 스키마로 정의하지만, Dynamic, Variant, JSON 타입을 통해 유연성을 제공합니다. 이를 통해 반정형 데이터를 수집할 수 있으며, Elasticsearch와 유사하게 동적 컬럼 생성 및 타입 추론이 가능합니다. 이와 비슷하게 Map 타입은 임의의 key-value 쌍을 저장할 수 있게 해 주지만, 키와 값 모두에 대해 단일 타입이 사용되도록 강제합니다.
ClickHouse의 타입 유연성에 대한 접근 방식은 더 투명하고 제어 가능하게 설계되어 있습니다. 수집 시 타입 충돌이 오류를 유발할 수 있는 Elasticsearch와 달리, ClickHouse는 Variant 컬럼에 서로 다른 타입의 데이터를 허용하고, JSON 타입을 사용한 스키마 진화를 지원합니다.
JSON을 사용하지 않는 경우 스키마는 정적으로 정의됩니다. 행에 대한 값이 제공되지 않으면 해당 컬럼은 Nullable로 정의되거나(ClickStack에서는 사용하지 않음) 해당 타입의 기본값으로 대체됩니다. 예를 들어 String 타입의 기본값은 빈 값입니다.
수집 및 변환
Elasticsearch는 인덱싱 전에 문서를 변환하기 위해 enrich, rename, grok 등의 프로세서를 사용하는 수집 파이프라인(ingest pipeline)을 사용합니다. ClickHouse에서는 증분형 materialized view를 사용하여 유사한 기능을 구현하며, 이를 통해 유입되는 데이터를 필터링하거나 변환하거나 보강하여 결과를 대상 테이블에 삽입할 수 있습니다. materialized view의 출력만 저장하면 되는 경우에는 데이터를 Null table engine에 삽입할 수도 있습니다. 이렇게 하면 materialized view의 결과만 유지되고 원본 데이터는 폐기되므로, 스토리지 공간을 절약할 수 있습니다.
데이터 보강(enrichment)을 위해 Elasticsearch는 문서에 컨텍스트를 추가하는 전용 enrich processors를 지원합니다. ClickHouse에서는 딕셔너리를 쿼리 시점과 수집 시점 모두에 사용할 수 있어 행을 보강할 수 있습니다. 예를 들어 IP를 위치에 매핑하거나, 삽입 시점에 user agent 조회를 적용할 수 있습니다.
Query languages
Elasticsearch는 여러 쿼리 언어 including DSL, ES|QL, EQL 및 KQL (Lucene 스타일) 쿼리를 지원하지만, 조인에 대한 지원은 제한적이며 ES|QL을 통한 left outer joins만 사용할 수 있습니다. ClickHouse는 모든 조인 유형, window functions, 서브쿼리(및 correlated), 그리고 CTE를 포함한 완전한 SQL 구문을 지원합니다. 이는 관측성 신호와 비즈니스 또는 인프라 데이터 간을 연관시켜야 하는 경우에 큰 장점입니다.
In ClickStack, the UI provides a Lucene-compatible search interface for ease of transition, alongside full SQL support via the ClickHouse backend. 이 문법은 Elastic query string 문법과 유사합니다. 보다 정확한 문법 비교는 "Searching in ClickStack and Elastic"에서 확인할 수 있습니다.
파일 형식과 인터페이스
Elasticsearch는 JSON(및 제한적인 CSV) 수집을 지원합니다. ClickHouse는 Parquet, Protobuf, Arrow, CSV 등을 포함하여 70개가 넘는 파일 형식을 수집과 내보내기 모두에 대해 지원합니다. 이를 통해 외부 파이프라인 및 도구와 더 쉽게 통합할 수 있습니다.
두 시스템 모두 REST API를 제공하지만, ClickHouse는 지연 시간이 짧고 처리량이 높은 상호 작용을 위한 네이티브 프로토콜도 제공합니다. 네이티브 인터페이스는 HTTP보다 쿼리 진행 상황, 압축 및 스트리밍을 더 효율적으로 지원하며, 대부분의 프로덕션 환경에서 수집의 기본 인터페이스로 사용됩니다.
Indexing and storage
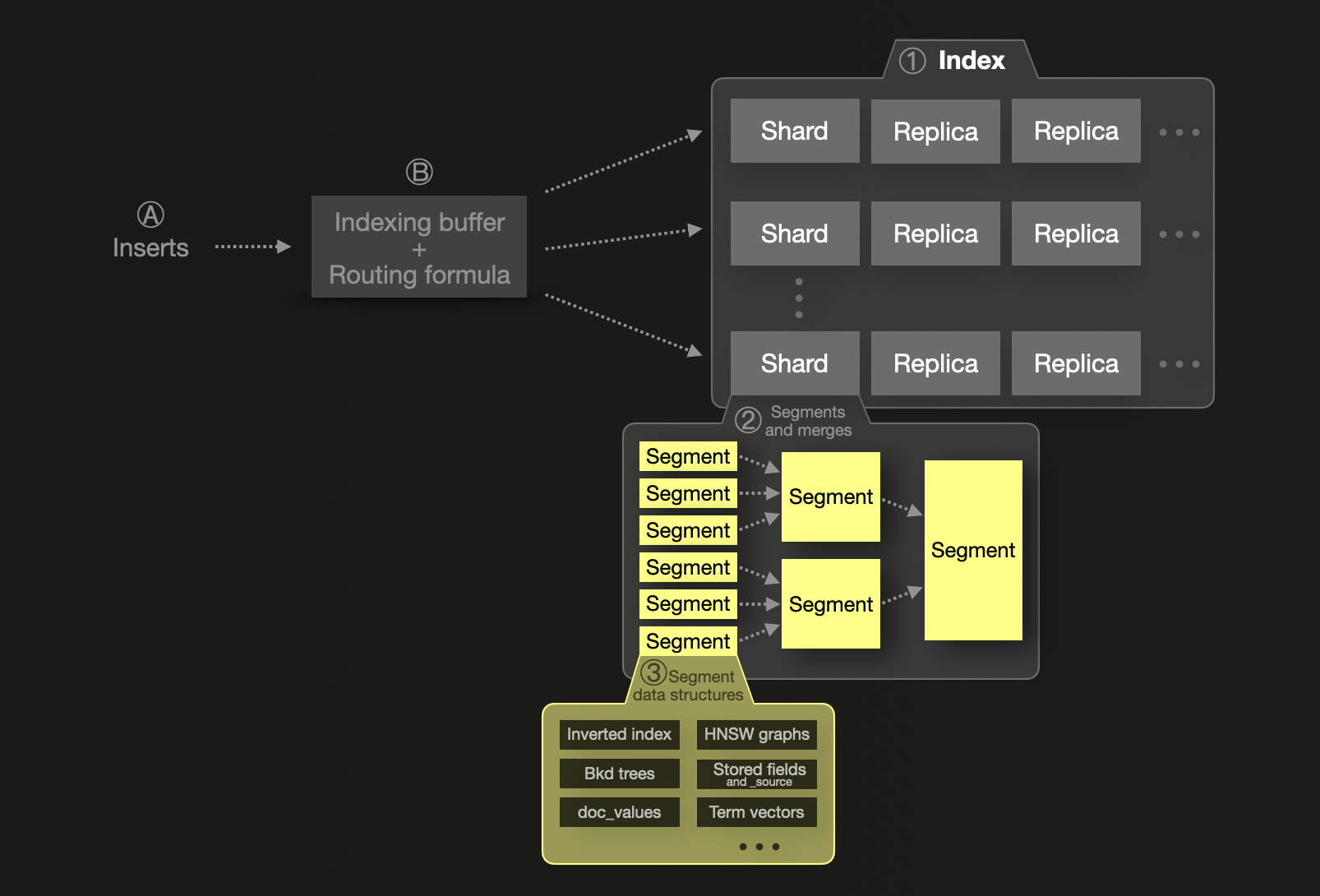
샤딩 개념은 Elasticsearch의 확장성 모델에서 근본적인 요소입니다. 각 ① index는 **샤드(shard)**로 분할되며, 각 샤드는 디스크의 세그먼트로 저장된 물리적인 Lucene 인덱스입니다. 하나의 샤드는 내결함성을 위해 replica shard라고 불리는 하나 이상의 물리적 복사본을 가질 수 있습니다. 확장성을 위해 샤드와 레플리카는 여러 노드에 분산될 수 있습니다. 단일 샤드 ②는 하나 이상의 불변(immutable) 세그먼트로 구성됩니다. 세그먼트는 Elasticsearch의 기반이 되는 색인 및 검색 기능을 제공하는 Java 라이브러리 Lucene의 기본 색인 구조입니다.
Ⓐ 새로 삽입된 문서는 Ⓑ 먼저 메모리 내 인덱싱 버퍼로 들어가며, 기본적으로 1초마다 플러시됩니다. 라우팅 수식을 사용해 플러시된 문서의 대상 샤드를 결정하고, 해당 샤드에 대해 디스크에 새로운 세그먼트를 기록합니다. 쿼리 효율성을 높이고 삭제되었거나 업데이트된 문서의 물리적 삭제를 가능하게 하기 위해, 세그먼트는 백그라운드에서 지속적으로 병합되어 더 큰 세그먼트가 되며, 최대 5GB 크기에 도달할 때까지 계속됩니다. 필요하다면 더 큰 세그먼트로 강제 병합하는 것도 가능합니다.
Elasticsearch는 JVM 힙과 메타데이터 오버헤드 때문에 샤드 크기를 50GB 또는 2억 개 문서 수준으로 맞출 것을 권장합니다. 또한 샤드당 20억 개 문서의 하드 한도가 있습니다. Elasticsearch는 쿼리를 샤드 단위로 병렬 처리하지만, 각 샤드는 단일 스레드로 처리되므로 과도한 샤드 분할(오버 샤딩)은 비용이 많이 들고 비효율적입니다. 이로 인해 샤딩과 확장은 본질적으로 밀접하게 연결되며, 성능 확장을 위해서는 더 많은 샤드(및 노드)가 필요하게 됩니다.
Elasticsearch는 모든 필드를 inverted indices에 인덱싱하여 빠른 검색을 제공하며, 필요에 따라 집계, 정렬 및 스크립트 필드 접근을 위해 doc values를 사용합니다. 숫자 및 지리 정보 필드는 지리 공간 데이터와 숫자 및 날짜 범위 검색을 위해 Block K-D trees를 사용합니다.
중요한 점으로, Elasticsearch는 전체 원본 문서를 _source에 (LZ4, Deflate 또는 ZSTD로 압축하여) 저장하는 반면, ClickHouse는 별도의 문서 표현을 저장하지 않습니다. 데이터는 쿼리 시점에 컬럼에서 재구성되며, 이로 인해 저장 공간을 절약합니다. 이와 같은 기능은 Synthetic _source를 사용해 Elasticsearch에서도 구현할 수 있지만, 몇 가지 제약이 있습니다. _source를 비활성화하면 ClickHouse에는 적용되지 않는 여러 영향도 발생합니다.
Elasticsearch에서는 index mappings(ClickHouse에서의 테이블 스키마와 동등)이 필드 타입과, 이를 영속화하고 쿼리하기 위해 사용되는 데이터 구조를 제어합니다.
반면 ClickHouse는 **컬럼 지향(column-oriented)**이며, 모든 컬럼은 독립적으로 저장되지만 항상 테이블의 기본/정렬 키로 정렬됩니다. 이 정렬은 희소 기본 인덱스(primary index)를 가능하게 하며, ClickHouse가 쿼리 실행 중 데이터 일부를 효율적으로 건너뛸 수 있도록 합니다. 쿼리가 기본 키 필드로 필터링될 때, ClickHouse는 각 컬럼에서 관련된 파트만 읽어 디스크 I/O를 크게 줄이고 성능을 향상합니다. 이는 모든 컬럼에 완전한 인덱스가 없어도 가능합니다.
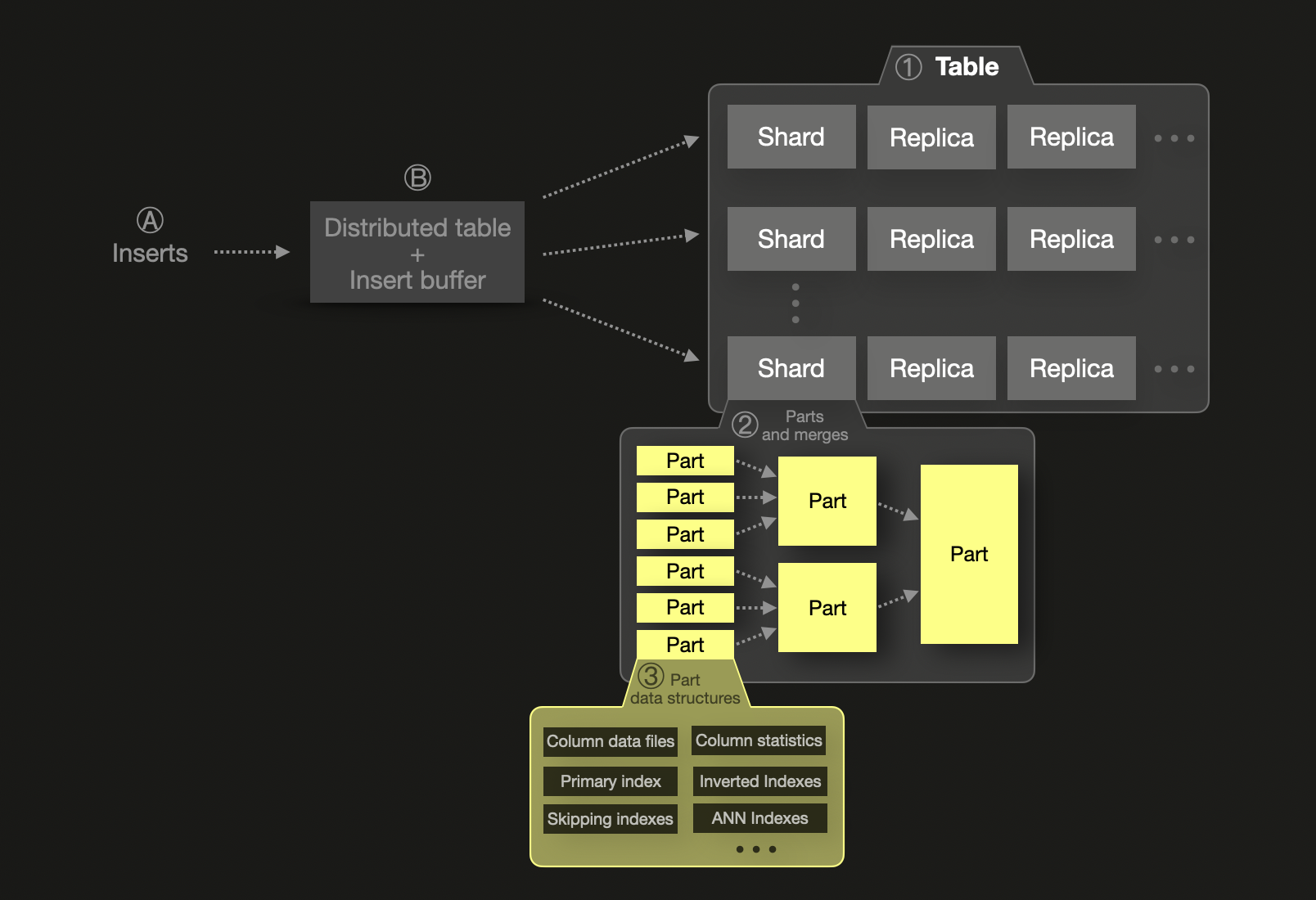
ClickHouse는 또한 선택된 컬럼에 대해 인덱스 데이터를 미리 계산하여 필터링을 가속화하는 skip indexes를 지원합니다. 이는 명시적으로 정의해야 하지만 성능을 크게 향상할 수 있습니다. 또한 ClickHouse에서는 컬럼별로 compression codecs와 압축 알고리즘을 지정할 수 있는데, 이는 Elasticsearch에서 지원하지 않는 기능입니다(Elasticsearch의 compression은 _source JSON 저장에만 적용됩니다).
ClickHouse도 세그먼트를 지원하지만, 그 모델은 수직 확장에 유리하도록 설계되어 있습니다. 단일 세그먼트는 수조 개의 행을 저장할 수 있으며, 메모리·CPU·디스크가 허용하는 한 효율적으로 동작합니다. Elasticsearch와 달리 세그먼트당 엄격한 행 제한이 없습니다. ClickHouse의 세그먼트는 논리적인 개념으로, 사실상 개별 테이블이며, 단일 노드의 용량을 초과하지 않는 한 파티션이 필요하지 않습니다. 이는 일반적으로 디스크 크기 제약으로 인해 발생하며, 수평 확장이 필요할 때에만 세그먼트를 ① 도입하여 복잡성과 오버헤드를 줄입니다. 이 경우 Elasticsearch와 마찬가지로 하나의 세그먼트는 데이터의 일부를 보유합니다. 단일 세그먼트 내의 데이터는 ② 변경 불가능한 데이터 파트의 집합으로 구성되며, 각 파트는 ③ 여러 데이터 구조를 포함합니다.
ClickHouse 세그먼트 내에서의 처리는 완전히 병렬화되며, 노드 간 데이터 이동에 따른 네트워크 비용을 피하기 위해 수직 확장을 권장합니다.
ClickHouse에서 Insert는 기본적으로 동기식으로 동작하며, 커밋이 완료된 후에만 쓰기가 확인됩니다. 다만 Elasticsearch와 유사한 버퍼링 및 배치를 위해 비동기 Insert로 설정할 수 있습니다. asynchronous data inserts를 사용하는 경우, Ⓐ 새로 삽입된 행은 먼저 Ⓑ 메모리 내 insert 버퍼에 기록되며, 이 버퍼는 기본적으로 200밀리초마다 플러시됩니다. 여러 세그먼트를 사용하는 경우, 새로 삽입된 행을 대상 세그먼트로 라우팅하기 위해 distributed table을 사용합니다. 디스크 상의 세그먼트에는 새로운 파트가 기록됩니다.
Distribution and replication
Elasticsearch와 ClickHouse 모두 확장성과 장애 허용을 위해 클러스터, 세그먼트(shard), 레플리카를 사용하지만, 구현 방식과 성능 특성은 상당히 다릅니다.
Elasticsearch는 복제를 위해 primary-secondary 모델을 사용합니다. 데이터가 primary 세그먼트에 기록되면, 하나 이상의 레플리카로 동기식으로 복사됩니다. 이 레플리카는 노드 전반에 분산된 완전한 세그먼트로, 중복성을 보장합니다. Elasticsearch는 필요한 모든 레플리카가 작업을 확인한 이후에만 쓰기를 승인합니다. 이 모델은 **순차적 일관성(sequential consistency)**에 가까운 특성을 제공하지만, 전체 동기화 전에 레플리카에서 dirty read가 발생할 수 있습니다. **마스터 노드(master node)**는 세그먼트 할당, 상태(health), 리더 선출을 관리하며 클러스터를 조정합니다.
반면 ClickHouse는 기본적으로 eventual consistency를 사용하며, ZooKeeper의 경량 대안인 Keeper에 의해 조정됩니다. 쓰기는 어떤 레플리카로든 직접 보내거나, 자동으로 레플리카를 선택하는 분산 테이블(distributed table)을 통해 전송할 수 있습니다. 복제는 비동기식으로 수행되며, 쓰기가 승인된 이후에 다른 레플리카로 변경 사항이 전파됩니다. 더 엄격한 보장을 위해, ClickHouse는 쓰기가 레플리카 전반에 커밋된 이후에만 승인되는 순차적 일관성을 지원하지만, 성능에 미치는 영향으로 인해 이 모드는 거의 사용되지 않습니다. 분산 테이블은 여러 세그먼트에 걸친 접근을 통합하여 SELECT 쿼리를 모든 세그먼트로 전달하고 결과를 병합합니다. INSERT 작업 시에는 데이터를 세그먼트 전반에 균등하게 라우팅하여 부하를 분산합니다. ClickHouse의 복제는 매우 유연하여, 어떤 레플리카(세그먼트의 복사본)든 쓰기를 수용할 수 있으며 모든 변경 사항은 다른 레플리카로 비동기식으로 동기화됩니다. 이러한 아키텍처는 장애나 유지 관리 중에도 쿼리 처리가 중단되지 않게 해 주며, 재동기화는 자동으로 처리되므로 데이터 계층에서 primary-secondary 강제 구조가 필요하지 않습니다.
ClickHouse Cloud에서는, 단일 세그먼트가 객체 스토리지에 의해 지원되는(shared-nothing) 컴퓨트 모델을 도입합니다. 이는 전통적인 레플리카 기반 고가용성을 대체하며, 하나의 세그먼트를 여러 노드가 동시에 읽고 쓸 수 있도록 합니다. 스토리지와 컴퓨트를 분리함으로써, 명시적인 레플리카 관리 없이도 탄력적인 확장이 가능해집니다.
요약하면 다음과 같습니다.
- Elastic: 세그먼트는 JVM 메모리에 결합된 물리적인 Lucene 구조입니다. 과도한 세그먼트 분할은 성능 저하를 초래합니다. 복제는 마스터 노드가 조정하는 동기식 복제입니다.
- ClickHouse: 세그먼트는 논리적이며 수직 확장이 가능하고, 매우 효율적인 로컬 실행을 제공합니다. 복제는 비동기식(필요하면 순차적)이며, 조정 부담이 적습니다.
결국 ClickHouse는 세그먼트 튜닝 필요성을 최소화하면서도 필요할 때 강력한 일관성 보장을 제공하여, 대규모 환경에서 단순성과 성능을 중시하는 접근 방식을 취합니다.
중복 제거와 라우팅
Elasticsearch는 문서의 _id를 기준으로 중복을 제거하고, 그에 따라 세그먼트로 라우팅합니다. ClickHouse는 기본 행 식별자를 저장하지 않지만 **삽입 시점 중복 제거(insert-time deduplication)**를 지원하여, 사용자가 실패한 삽입을 안전하게 재시도할 수 있도록 합니다. 더 세밀하게 제어하려면 ReplacingMergeTree 및 기타 테이블 엔진을 사용하여 특정 컬럼을 기준으로 중복 제거를 수행할 수 있습니다.
Elasticsearch의 인덱스 라우팅은 특정 문서가 항상 특정 세그먼트로 라우팅되도록 보장합니다. ClickHouse에서는 **세그먼트 키(shard key)**를 정의하거나 Distributed 테이블을 사용하여 이와 유사한 데이터 지역성을 달성할 수 있습니다.
집계와 실행 모델
두 시스템 모두 데이터 집계를 지원하지만, ClickHouse는 통계, 근사, 특수 분석 함수 등을 포함하여 더 많은 함수를 제공합니다.
관측성 사용 사례에서 집계의 가장 일반적인 활용 중 하나는 특정 로그 메시지나 이벤트가 얼마나 자주 발생하는지 계산하고(빈도가 비정상적인 경우 경고를 트리거하는 것)입니다.
Elasticsearch에서 ClickHouse의 SELECT count(*) FROM ... GROUP BY ... SQL 쿼리와 동등한 기능은 terms aggregation이며, 이는 Elasticsearch의 bucket aggregation에 해당합니다.
ClickHouse의 GROUP BY와 count(*) 조합과 Elasticsearch의 terms aggregation은 기능 면에서는 일반적으로 동등하지만, 구현 방식, 성능, 결과 품질 측면에서는 크게 다릅니다.
Elasticsearch에서 이 집계는 쿼리된 데이터가 여러 세그먼트에 걸쳐 있을 때, "top-N" 쿼리에서 결과를 추정합니다(예: 카운트 기준 상위 10개 호스트). 이러한 추정은 속도를 향상시키지만 정확성을 떨어뜨릴 수 있습니다. doc_count_error_upper_bound를 확인하고 shard_size 파라미터를 늘리면 이 오류를 줄일 수 있지만, 그 대가로 메모리 사용량 증가와 쿼리 성능 저하가 발생합니다.
또한 Elasticsearch에서는 모든 버킷 집계에 대해 size 설정이 필요하며, 명시적으로 제한을 설정하지 않고는 모든 고유 그룹을 반환하는 방법이 없습니다. 고카디널리티(high-cardinality) 집계는 max_buckets 한계에 도달할 위험이 있거나, composite aggregation을 사용해 페이지네이션해야 하는데, 이는 종종 복잡하고 비효율적입니다.
반면 ClickHouse는 기본적으로 정확한 집계를 수행합니다. count(*)와 같은 함수는 별도의 설정 조정 없이도 정확한 결과를 반환하므로, 쿼리 동작이 더 단순하고 예측 가능합니다.
ClickHouse는 크기 제한을 두지 않습니다. 대규모 데이터셋에 대해 제한 없이 group-by 쿼리를 수행할 수 있습니다. 메모리 임계값을 초과하면 ClickHouse는 디스크로 데이터를 스필(spill)할 수 있습니다. 기본 키 접두사(prefix)로 group by를 수행하는 집계는 특히 효율적이며, 종종 매우 적은 메모리만으로 실행됩니다.
Execution model
위에서 설명한 차이점은 Elasticsearch와 ClickHouse의 실행 모델에서 비롯됩니다. 두 시스템은 쿼리 실행과 병렬 처리에 근본적으로 다른 접근 방식을 취합니다.
ClickHouse는 최신 하드웨어에서의 효율을 극대화하도록 설계되었습니다. 기본적으로 ClickHouse는 CPU 코어가 N개인 머신에서 SQL 쿼리를 N개의 동시 실행 레인으로 실행합니다:
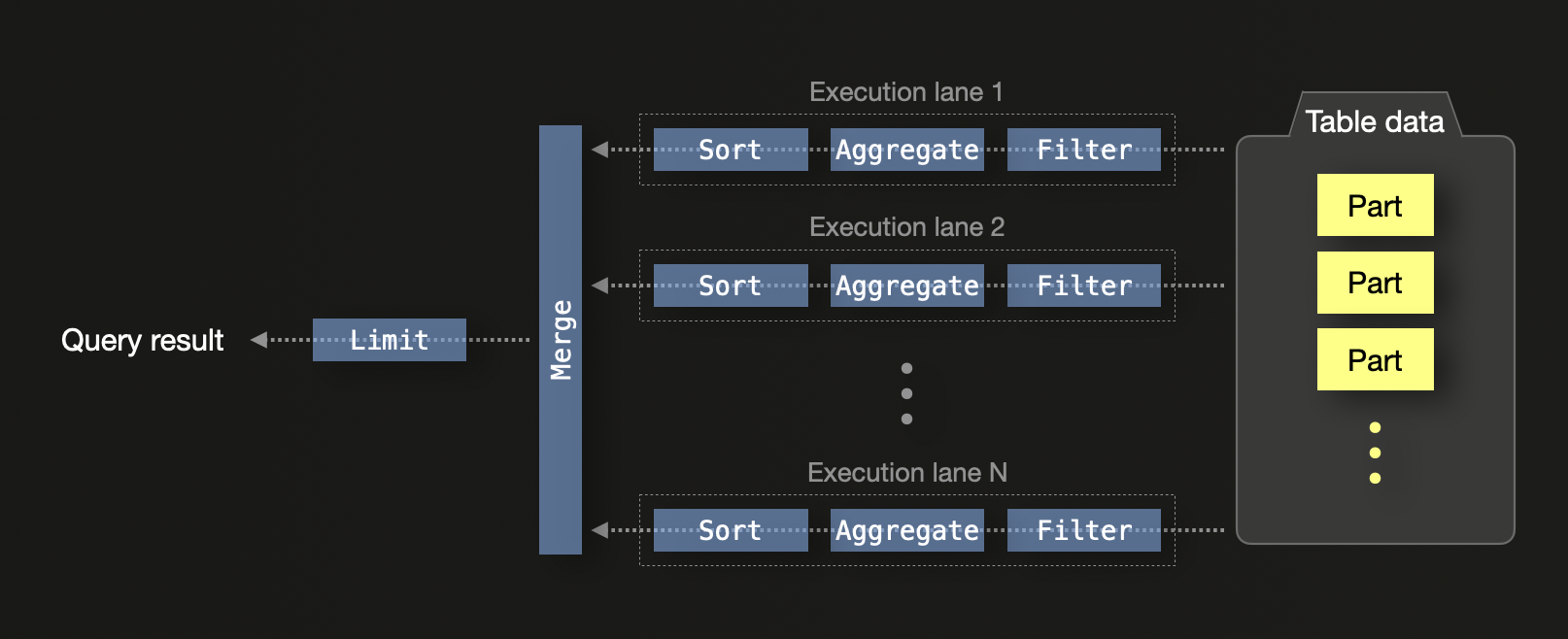
단일 노드에서는 실행 레인이 데이터를 서로 독립적인 범위로 분할하여 CPU 스레드 전반에 걸쳐 동시 처리가 가능하도록 합니다. 여기에는 필터링, 집계, 정렬이 포함됩니다. 각 레인에서 계산된 로컬 결과는 최종적으로 병합되며, 쿼리에 LIMIT 절이 포함된 경우 LIMIT 연산자가 적용됩니다.
쿼리 실행은 다음과 같이 추가로 병렬화됩니다:
- SIMD 벡터화: 열 지향 데이터에 대한 연산은 CPU SIMD 명령 (예: AVX512)를 사용하여 값을 배치 단위로 처리합니다.
- 클러스터 수준 병렬성: 분산 환경에서는 각 노드가 쿼리를 로컬에서 처리합니다. 부분 집계 상태는 시작 노드로 스트리밍되어 병합됩니다. 쿼리의
GROUP BY키가 세그먼트 키와 일치하는 경우, 병합을 최소화하거나 완전히 피할 수 있습니다.
이 모델은 코어 및 노드 전반에 걸친 효율적인 스케일링을 가능하게 하여 ClickHouse가 대규모 분석에 적합하도록 합니다. 부분 집계 상태를 사용하면 서로 다른 스레드와 노드에서 생성된 중간 결과를 정확도를 잃지 않고 병합할 수 있습니다.
반면 Elasticsearch는 대부분의 집계에서 사용 가능한 CPU 코어 수와 관계없이 세그먼트당 하나의 스레드를 할당합니다. 이 스레드들은 세그먼트 로컬 top-N 결과를 반환하며, 이는 조정(coordinating) 노드에서 병합됩니다. 이러한 방식은 시스템 자원을 충분히 활용하지 못할 수 있고, 특히 자주 등장하는 용어가 여러 세그먼트에 분산된 경우 전역 집계에서 잠재적인 부정확성을 초래할 수 있습니다. shard_size 파라미터를 증가시키면 정확도를 개선할 수 있지만, 그 대가로 더 높은 메모리 사용량과 쿼리 지연 시간이 발생합니다.
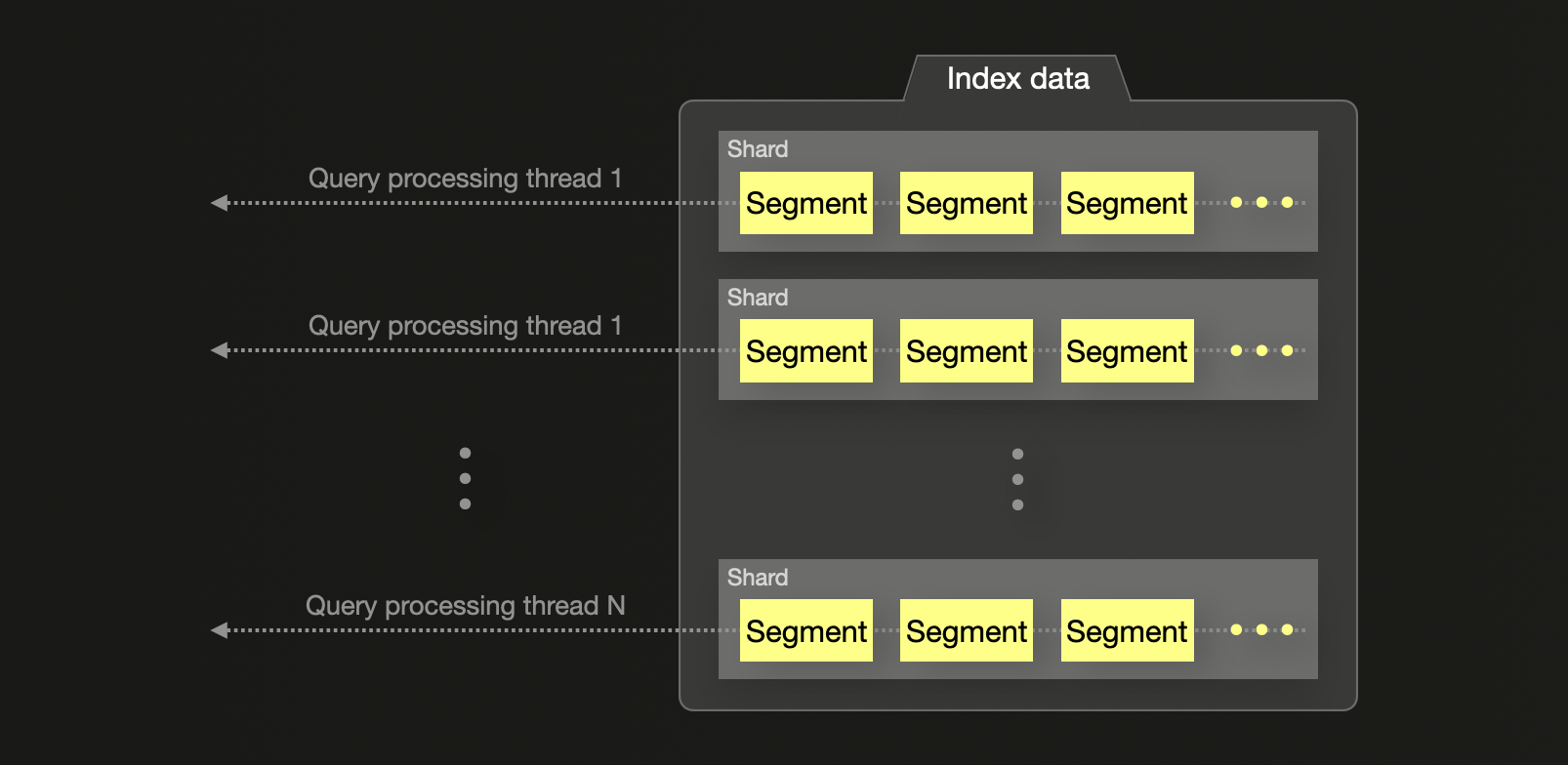
요약하면, ClickHouse는 더 세밀한 수준의 병렬성과 하드웨어 자원에 대한 더 높은 제어력을 바탕으로 집계와 쿼리를 실행하는 반면, Elasticsearch는 더 경직된 제약을 가진 세그먼트 기반 실행 방식에 의존합니다.
각 기술에서 집계 메커니즘이 동작하는 방식에 대한 자세한 내용은 블로그 게시글 「ClickHouse vs. Elasticsearch: The Mechanics of Count Aggregations」을 참고하기 바랍니다.
데이터 관리
Elasticsearch와 ClickHouse는 시계열 관측성 데이터를 관리하는 방식, 특히 데이터 보존, 롤오버, 계층형 스토리지 측면에서 근본적으로 상이한 접근 방식을 취합니다.
인덱스 수명 주기 관리 vs 네이티브 TTL
Elasticsearch에서는 장기 데이터 관리를 Index Lifecycle Management (ILM) 및 Data Streams를 통해 관리합니다. 이러한 기능을 사용하면 인덱스가 롤오버되는 시점(예: 특정 크기나 기간에 도달했을 때), 오래된 인덱스를 더 저렴한 스토리지(예: warm 또는 cold 계층)로 이동하는 시점, 그리고 최종적으로 삭제되는 시점을 규정하는 정책을 정의할 수 있습니다. 이는 Elasticsearch가 재세그먼트(re-sharding)를 지원하지 않으며, 세그먼트가 성능 저하 없이 무한정 커질 수 없기 때문에 필요합니다. 세그먼트 크기를 관리하고 효율적인 삭제를 지원하려면 새 인덱스를 주기적으로 생성하고 오래된 인덱스를 제거해야 하며, 이는 사실상 인덱스 수준에서 데이터를 순환시키는 방식입니다.
ClickHouse는 다른 접근 방식을 취합니다. 데이터는 일반적으로 단일 테이블에 저장되며 컬럼 또는 파티션 수준에서 TTL(time-to-live) 표현식을 사용하여 관리합니다. 데이터를 날짜 기준으로 파티션할 수 있으므로, 새 테이블을 생성하거나 인덱스 롤오버를 수행하지 않고도 효율적으로 삭제할 수 있습니다. 데이터가 시간이 지나 TTL 조건을 만족하면 ClickHouse가 이를 자동으로 제거하므로, 순환 관리를 위한 추가 인프라가 필요하지 않습니다.
스토리지 계층과 핫-웜 아키텍처
Elasticsearch는 서로 다른 성능 특성을 가진 스토리지 계층 사이에서 데이터를 이동시키는 hot-warm-cold-frozen 스토리지 아키텍처를 지원합니다. 이는 일반적으로 ILM을 통해 구성되며, 클러스터의 노드 역할과 연결됩니다.
ClickHouse는 MergeTree와 같은 네이티브 테이블 엔진을 통해 계층형 스토리지(tiered storage) 를 지원하며, 사용자 정의 규칙에 따라 오래된 데이터를 서로 다른 볼륨(volume)(예: SSD에서 HDD, 객체 스토리지로) 간에 자동으로 이동시킬 수 있습니다. 이를 통해 Elastic의 hot-warm-cold 접근 방식을 유사하게 구현할 수 있지만, 여러 노드 역할이나 클러스터를 관리해야 하는 복잡성은 없습니다.
ClickHouse Cloud에서는 이 과정이 더욱 원활해집니다. 모든 데이터가 객체 스토리지(예: S3) 에 저장되고, 컴퓨트 리소스는 스토리지와 분리되어 동작합니다. 데이터는 쿼리가 실행될 때까지 객체 스토리지에 그대로 두었다가, 쿼리 시점에 가져와 로컬(또는 분산 캐시)에 캐시됩니다. 이를 통해 Elastic의 frozen 계층과 유사한 비용 구조를 유지하면서 더 나은 성능 특성을 제공합니다. 이러한 접근 방식에서는 스토리지 계층 간에 데이터를 이동할 필요가 없어지므로, 핫-웜 아키텍처는 사실상 불필요해집니다.
롤업과 증분형 집계
Elasticsearch에서 rollup 또는 aggregate는 transforms라고 불리는 메커니즘을 사용해 구현됩니다. 이는 슬라이딩 윈도우 모델을 사용하여 시계열 데이터를 고정된 간격(예: 매시간 또는 매일)으로 요약하는 데 사용됩니다. 이러한 transform은 하나의 인덱스에서 데이터를 집계하여 결과를 별도의 rollup 인덱스에 기록하는 반복 실행되는 백그라운드 작업으로 구성됩니다. 이를 통해 고카디널리티 원시 데이터를 반복해서 스캔하지 않고도 장기간 범위의 쿼리 비용을 줄일 수 있습니다.
다음 다이어그램은 transform이 어떻게 동작하는지 추상적으로 보여 줍니다(사전에 집계 값을 미리 계산해 두려는 동일한 버킷에 속하는 모든 문서는 파란색으로 표시합니다):
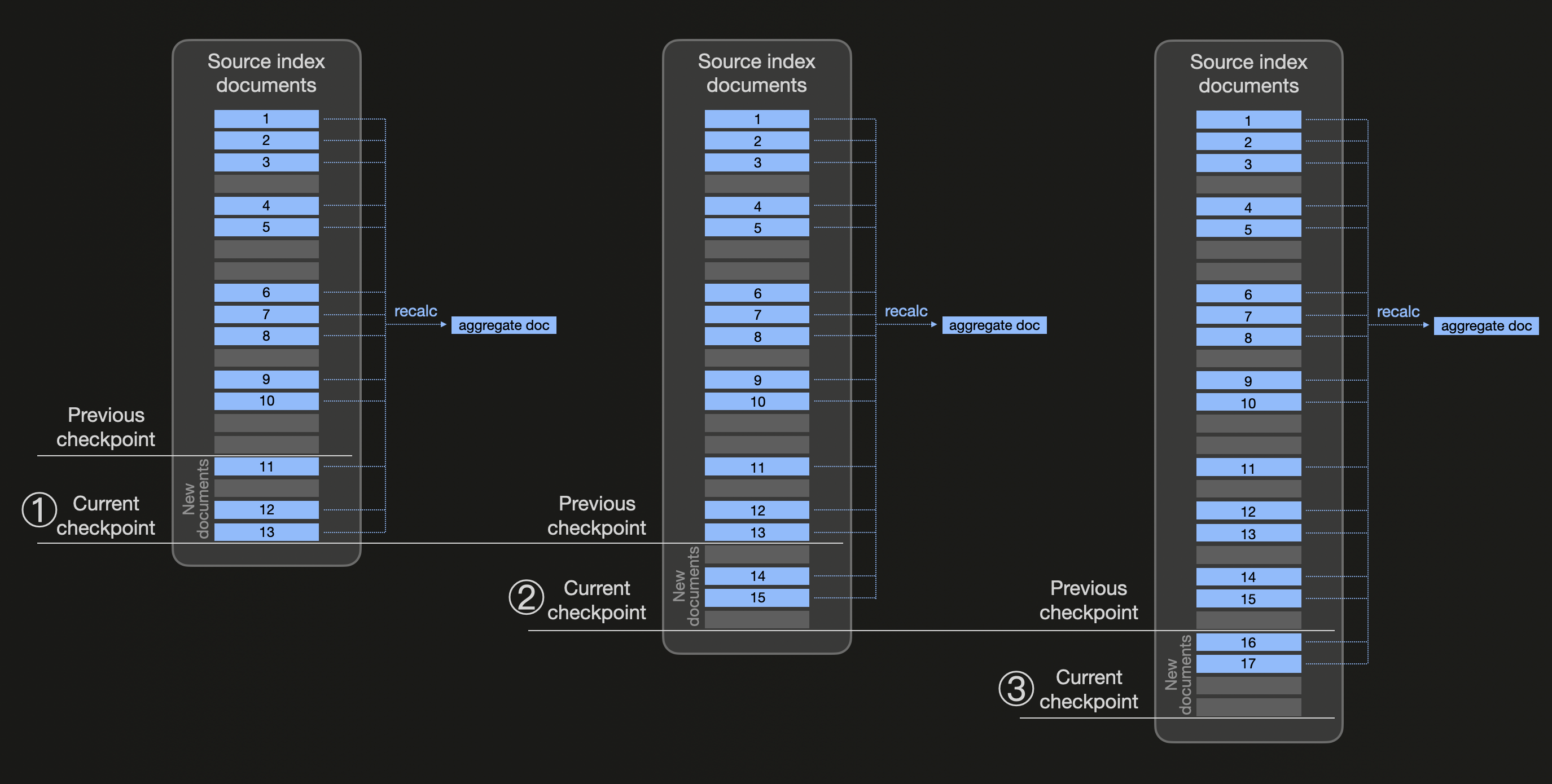
연속 transform은 구성 가능한 체크 간격 시간(기본값 1분인 transform frequency)을 기준으로 transform checkpoint를 사용합니다. 위 다이어그램에서는 ① 체크 간격 시간이 경과한 후 새로운 체크포인트가 생성된다고 가정합니다. 이제 Elasticsearch는 transform의 소스 인덱스에서 변경 사항을 확인하고, 이전 체크포인트 이후에 생성된 세 개의 새로운 blue 문서(11, 12, 13)를 감지합니다. 이에 따라 소스 인덱스는 존재하는 모든 blue 문서로 필터링되고, composite aggregation(결과 페이지네이션을 활용하기 위해)을 사용하여 집계 값이 다시 계산됩니다(그리고 대상 인덱스는 이전 집계 값을 포함하고 있던 문서를 대체하는 문서로 업데이트됩니다). 마찬가지로 ②와 ③에서도, 변경 사항을 확인하고 동일한 blue 버킷에 속하는 모든 기존 문서로부터 집계 값을 다시 계산하는 방식으로 새로운 체크포인트가 처리됩니다.
ClickHouse는 근본적으로 다른 접근 방식을 취합니다. 데이터를 주기적으로 다시 집계하는 대신, ClickHouse는 데이터를 삽입 시점에 변환하고 집계하는 증분형 materialized view를 지원합니다. 새 데이터가 소스 테이블에 기록되면, materialized view는 미리 정의된 SQL 집계 쿼리를 새로 삽입된 블록에 대해서만 실행하고, 집계된 결과를 대상 테이블에 기록합니다.
이 모델은 ClickHouse가 partial aggregate state를 지원하기 때문에 가능합니다. 이는 나중에 병합할 수 있도록 저장 가능한 집계 함수의 중간 표현입니다. 이를 통해 쿼리는 빠르면서도 업데이트 비용이 낮은 부분 집계 결과를 유지할 수 있습니다. 집계가 데이터 도착 시점에 수행되므로, 비용이 많이 드는 반복 작업을 실행하거나 오래된 데이터를 다시 요약할 필요가 없습니다.
증분형 materialized view의 동작 메커니즘을 추상적으로 설명하면 다음과 같습니다(사전에 집계 값을 미리 계산해 두려는 동일한 그룹에 속하는 모든 행은 파란색으로 표시합니다):
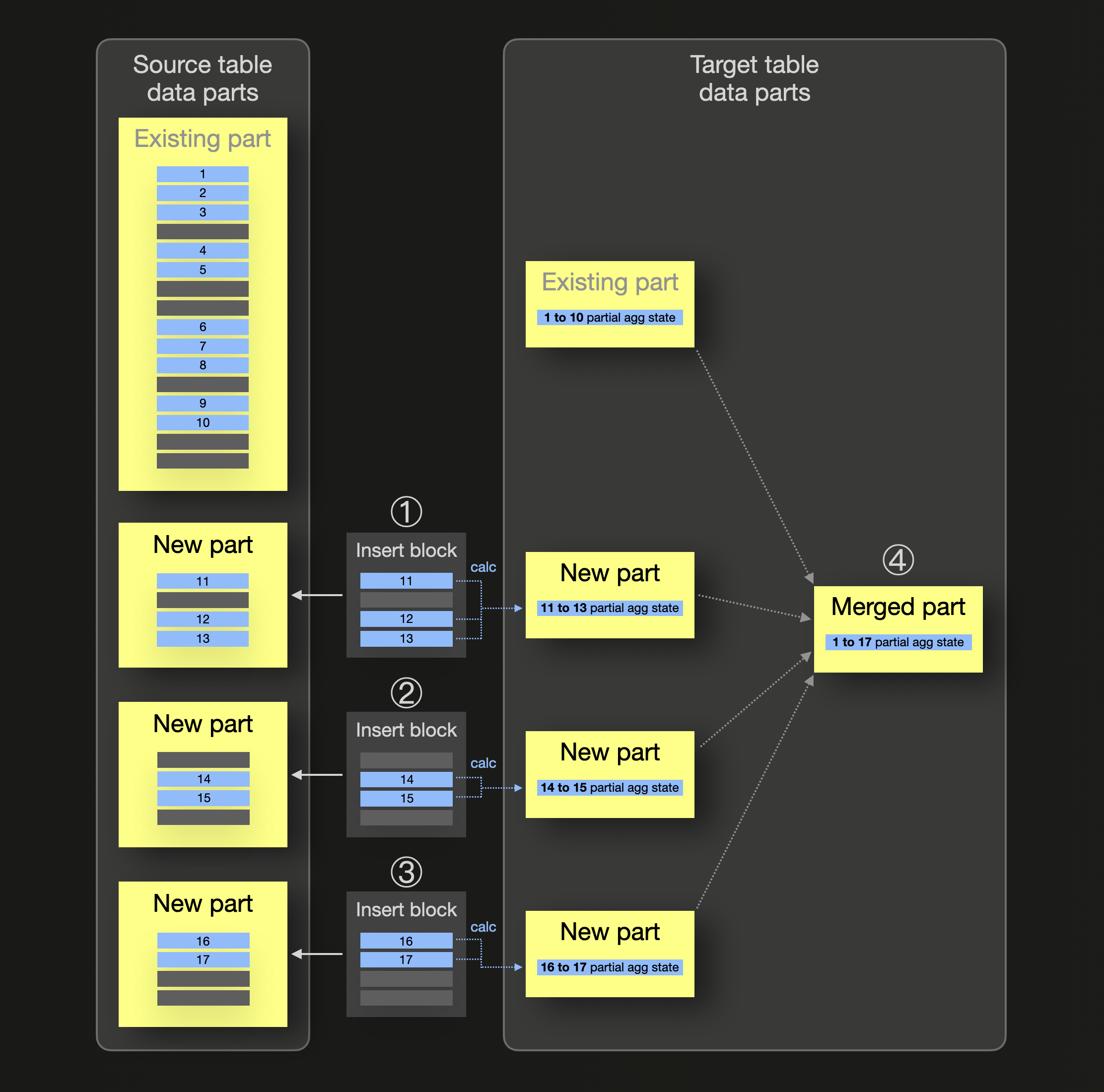
위 다이어그램에서 materialized view의 소스 테이블에는 이미 동일한 그룹에 속하는 일부 blue 행(1~10)을 저장하는 데이터 파트가 존재합니다. 이 그룹에 대해서는 view의 대상 테이블에도 blue 그룹에 대한 부분 집계 상태를 저장하는 데이터 파트가 이미 존재합니다. ① ② ③에서 새 행이 소스 테이블로 삽입될 때마다 각 삽입에 대해 대응되는 소스 테이블 데이터 파트가 생성되고, 동시에 새로 삽입된 행의 각 블록에 대해서만 부분 집계 상태가 계산되어 데이터 파트 형태로 materialized view의 대상 테이블에 삽입됩니다. ④ 백그라운드 파트 병합 동안 이러한 부분 집계 상태가 병합되면서, 결과적으로 데이터 집계가 증분적으로 이루어집니다.
aggregate function(90개 이상)과 aggregate function combinator와의 조합은 모두 부분 집계 상태를 지원합니다.
증분형 집계 관점에서 Elasticsearch와 ClickHouse를 비교하는 보다 구체적인 예시는 예제를 참고하십시오.
ClickHouse 방식의 장점은 다음과 같습니다:
- 항상 최신 상태의 집계: materialized view는 소스 테이블과 항상 동기화됩니다.
- 백그라운드 작업 불필요: 집계는 쿼리 시점이 아니라 삽입 시점에 수행됩니다.
- 향상된 실시간 성능: 최신 집계가 즉시 필요한 관측성 워크로드 및 실시간 분석에 이상적입니다.
- 조합 가능: materialized view는 다른 뷰 및 테이블과 계층화하거나 조인하여 더 복잡한 쿼리 가속 전략을 구성할 수 있습니다.
- 서로 다른 TTL: materialized view의 소스 테이블과 대상 테이블에 서로 다른 TTL 설정을 적용할 수 있습니다.
이 모델은 쿼리마다 수십억 개의 원시 레코드를 스캔하지 않고도 분당 오류율, 지연 시간, 상위 N개 분포와 같은 메트릭을 계산해야 하는 관측성 사용 사례에 특히 강력합니다.
Lakehouse 지원
ClickHouse와 Elasticsearch는 레이크하우스 통합에 대해 근본적으로 다른 접근 방식을 취합니다. ClickHouse는 Iceberg 및 Delta Lake와 같은 레이크하우스 포맷 위에서 쿼리를 실행할 수 있는 완전한 기능을 갖춘 쿼리 실행 엔진이며, AWS Glue 및 Unity catalog와 같은 데이터 레이크 카탈로그와도 통합합니다. 이러한 포맷은 Parquet 파일에 대한 효율적인 쿼리에 의존하며, ClickHouse는 이를 완전하게 지원합니다. ClickHouse는 Iceberg와 Delta Lake 테이블을 모두 직접 읽을 수 있어, 현대적인 데이터 레이크 아키텍처와의 원활한 통합이 가능합니다.
반면 Elasticsearch는 내부 데이터 포맷과 Lucene 기반 스토리지 엔진에 강하게 결합되어 있습니다. 레이크하우스 포맷이나 Parquet 파일을 직접 쿼리할 수 없으며, 이로 인해 현대적인 데이터 레이크 아키텍처에서의 활용이 제한됩니다. Elasticsearch는 쿼리를 실행하기 전에 데이터를 자체 독점 포맷으로 변환하여 적재해야 합니다.
ClickHouse의 레이크하우스 기능은 단순히 데이터를 읽는 것을 넘어 확장됩니다:
- 데이터 카탈로그 통합: ClickHouse는 AWS Glue와 같은 데이터 카탈로그와의 통합을 지원하여, 객체 스토리지에 있는 테이블을 자동으로 탐색하고 액세스할 수 있도록 합니다.
- 객체 스토리지 지원: S3, GCS, Azure Blob Storage에 상주하는 데이터를 데이터 이동 없이 네이티브하게 쿼리하는 기능을 지원합니다.
- 쿼리 페더레이션(Query federation): 외부 딕셔너리 및 테이블 함수를 사용하여 레이크하우스 테이블, 전통적인 데이터베이스, ClickHouse 테이블을 포함한 여러 소스에 걸쳐 데이터를 연관시킬 수 있는 기능을 제공합니다.
- 증분 적재: S3Queue 및 ClickPipes와 같은 기능을 사용하여 레이크하우스 테이블에서 로컬 MergeTree 테이블로 지속적으로 데이터를 적재하는 기능을 지원합니다.
- 성능 최적화: cluster functions를 사용하여 레이크하우스 데이터에 대해 분산 쿼리 실행을 수행함으로써 성능을 향상합니다.
이러한 기능 덕분에 ClickHouse는 레이크하우스 아키텍처를 도입하는 조직에 자연스럽게 적합하며, 데이터 레이크의 유연성과 컬럼형 데이터베이스의 성능을 모두 활용할 수 있게 합니다.
